Micro-segmentation
Micro-segmentation is used to send scoring data to a database or a search engine making it possible to personnalize results based on the user profile type.
Micro-segmentation is used to send scoring data to a database or a search engine making it possible to personnalize results based on the user profile type. Each item is assigned a score for each profile type.
Thanks to micro-segmentation, you can personalize list pages or search results, without impacting response time and without making a real-time call to the XO API. You can also use cache because it’s one-to-many personalization and not one-to-one.
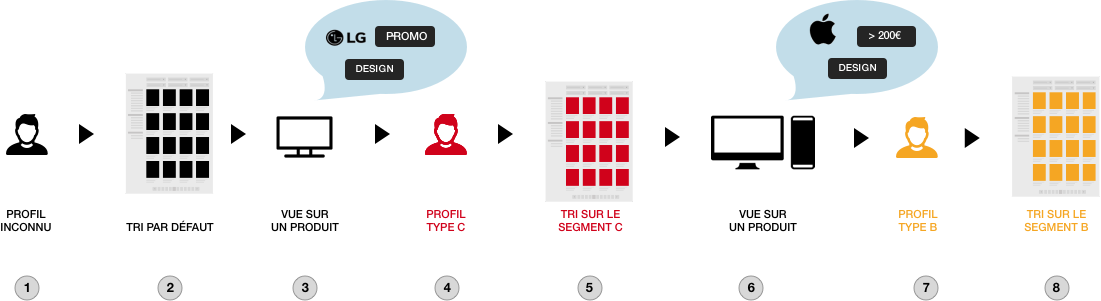
This is an example of the visitor qualification process:
The visitor comes to the website
He browses a list page or a search result. As the visitor is not known, a default ranking is displayed
The visitor visualizes a product that is associated to several specific tags
Product characteristics are used by clusterization algorithms to qualify the visitor. The closest profile type is calculated by XO algorithms. In this example, the visitor is a C type.
When the visitor comes back to the list, the list is ordered using the type C ranking.
The visitor visualizes an other product
XO will re-evaluate in realtime his profile type, taking into account this last activity. The profile type of a visitor can change. In this example, it changed to a B profile type.
If the visitor goes to a new list page, products will be ordered based on the B ranking.
Personalized ranking is base on two main parts:
Batch calculation of ranking for every profile type (usually between 10 and 100)
Real-time calculation of the closest profile type for each user (based on its activities and its profile type)
Personalised ranking
The first implementation step consists of retrieving ranking for each profile type. Usually, it’s done through a CSV file available on a FTP.
The file sent by XO have the following format name: items_#ID#.csv
It’s a CSV file with the following columns:
r0 to rn are the ranking value for each cluster. It’s a score between 0 and 1. For a visitor in the 3rd cluster, products must be sorted with a descending ordered based on column “Cluster 3”.
The file name contains a #ID#. It’s the id of the last generation (timestamp format). This id changes each time a new model is calculated (and a new ranking for each cluster is generated). It’s important to store this id somewhere so you know which generation is the generation you have loaded. You will see later that a profile is assigned to a cluster number for each generation.
The cluster 0 is the default ranking. Unknown visitors will be assigned to cluster 0 automatically.
Retrieve a user cluster
Each time a user makes an activity on the website (a view on a product for example), the cluster number assigned to this user will be returned by the XO API.
“58873e0fedcaae2325d7e6”is the algorithm id (predictorId) used to create clusters. Usually, there is only one algorithm used for creating clusters. Nevertheless, it’s possible to create clusters through different algorithms and if you want to test different clustering algorithms, this functionality allows you to retrieve the cluster number for each model.“1488289599922”is the generation ID. It’s the #ID# number in the name of the index files, available on the FTP. It’s possible to have one or two generations. We keep in memory the last generation and the previous one, so you can keep calling the previous generation while loading the new one in your database. Each generation ID is a timestamp. The last generation is always the one with the biggest ID.“5”and“7”: are the cluster number to use for this visitor. You have to sort products based on the corresponding column in the index file.
You need to save the generation ID each time you load a new index so you can keep calling the previous cluster number, and switch as soon as your new index is loaded.
Last updated